Free Uncensored AI: How to Run Local LLM API on Google Colab (2026)
A practical 2026 guide to using Google Colab as a disposable LLM host: what fits on the free tier, where the limits really are, and how to expose a stable API without pretending the setup is production-grade.
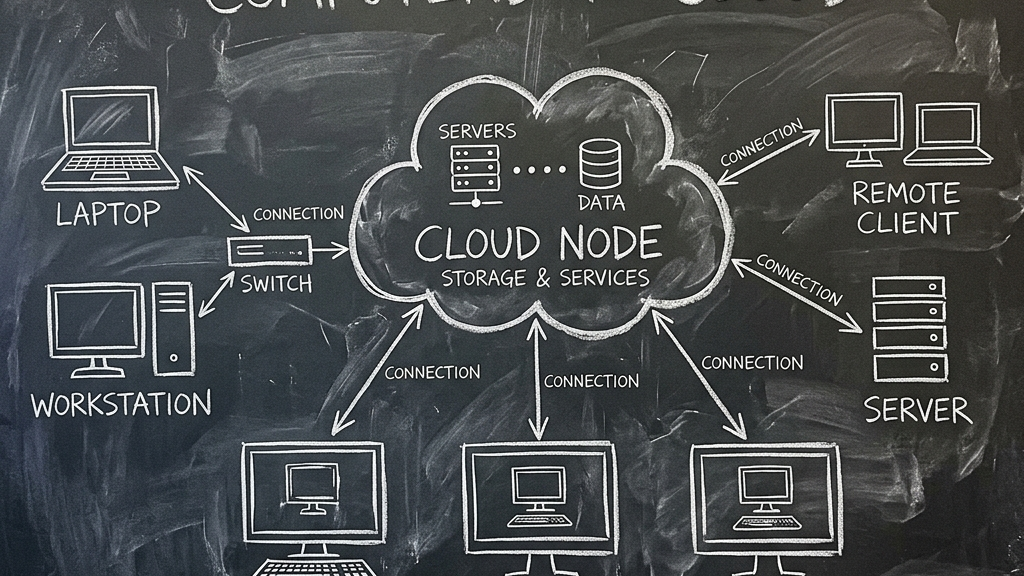
There is a certain kind of bad advice that flourishes every time API prices go up, and it usually sounds like: "just buy a GPU."
That answer skips over the obvious part. A lot of people do not have the cash, the space, the thermal headroom, or the patience to turn a room into a small inference furnace. They want a temporary box with enough VRAM to host a decent open model, enough control to avoid the usual sanitized cloud behavior, and a URL their own frontend can hit from elsewhere.
For these users, Google Colab keeps reappearing in this conversation—it runs in someone else's data center, meaning privacy is limited in the strict sense and stability is worse than people want. It is a disposable rented window into someone else's GPU pool. Used correctly, though, it can function as a cheap laboratory for roleplay, agent testing, prompt work, and UI experiments. Used incorrectly, it becomes a three-hour debugging session followed by a runtime reset.
The right way to think about Colab in 2026 is simple: it is a volatile staging ground for local-style control.
What does the free tier actually give you?
However, the free-tier dream still lives on screenshots from older years. People remember surprise allocations, generous quotas, magical sessions, the occasional lucky hardware draw.
By 2026 the picture is less romantic and more useful.
Most free users land on a T4 with 16GB of VRAM. That number matters more than the brand does. After CUDA overhead, you are usually working with roughly 15GB of genuinely usable space. That is enough for compact open models, mid-size quantized models, and a fairly serious amount of experimentation if you respect the cache.
Respecting the cache turns out to be the entire game because weight size is only the first bill. The KV cache arrives later and charges rent for every long conversation, every stuffed lorebook, every codebase dump, and every bad habit of keeping too much history alive because the machine has not complained yet. A quantized 8B or 9B model is comfortable. A 14B class model can work if you keep context disciplined. Once people start dreaming about giant context windows, the runtime usually reminds them that physics has not been deprecated.
So the viable zone looks like this:
- 8B to 9B class models if you want headroom and decent throughput.
- 12B to 14B class models if you are careful with context and quantization.
- Anything beyond that only if you enjoy flirting with out-of-memory failures.
The important correction is that Colab free tier is not for maximalism. It is for leverage.
The setup that survives contact with reality
If your goal is to expose a usable API in minutes, Ollama remains the least theatrical path.
Here is the production-tested, copy-pasteable Jupyter Notebook cell template designed to get you up and running on a T4 GPU in less than two minutes.
Cell 1: Prerequisites & Ollama Installation
# Update package index and install required hardware diagnostics
sudo apt update
sudo apt install -y pciutils lshw zstandard
# Install Ollama directly to the system bin
curl -fsSL https://ollama.com/install.sh | sh
# Confirm GPU detection (look for CUDA Driver Version and Tesla T4)
nvidia-smi
Cell 2: Non-Blocking Background Daemon Initialization
To prevent the notebook environment from stalling, we must instantiate the Ollama service as an asynchronous background subprocess using Python:
import os
import subprocess
import time
# Configure host binding and CORS allowance (CRITICAL for web clients)
os.environ['OLLAMA_HOST'] = '127.0.0.1:11434'
os.environ['OLLAMA_ORIGINS'] = '*'
# Launch the server as a non-blocking background daemon
print("Initializing Ollama Daemon...")
subprocess.Popen(['ollama', 'serve'])
# Provide a mandatory 10-second grace period for full initialization
time.sleep(10)
print("Daemon initialization complete. Port 11434 is now listening.")
Cell 3: Model Ingestion and Verification
import subprocess
import ollama
# Pull the optimized roleplay model slug
print("Downloading qwen3.5:9b-uncensored...")
subprocess.run(["ollama", "pull", "qwen3.5:9b-uncensored"], check=True)
# Run a quick generation test directly from the Python SDK to confirm execution
print("Verifying model generation...")
response = ollama.chat(model='qwen3.5:9b-uncensored', messages=[
{'role': 'user', 'content': 'Hello! Respond with a single short sentence.'}
])
print("\nTest Output:\n", response['message']['content'])
That model class tends to be the sweet spot for free Colab use because it leaves room for conversation instead of spending the whole session negotiating memory pressure.
If you prefer raw llama.cpp, use it because you need lower-level control over cache quantization or server flags, not because you enjoy reinventing a wrapper that already works. Colab is already unstable enough. Saving purity points in a disposable runtime is usually pointless.
Your tunnel choice determines whether the setup feels temporary or deranged
This is where a lot of guides go soft in the head.
They get the model loaded, see tokens streaming, and then treat endpoint exposure as a footnote. In practice, the network layer decides whether the whole thing is usable.
Ngrok is still the quick demo choice. If you need a URL in minutes, it works. It also keeps behaving like a demo service: session limits, random domains, more friction than people remember, and enough churn that every downstream client has to be babysat.
To establish a zero-configuration, zero-account Cloudflare Tunnel (trycloudflare) directly from a Python cell:
import subprocess
import threading
# Run cloudflared to expose our local Ollama port (11434) to a random public URL
def establish_cloudflare_tunnel():
# We download the cloudflared binary first if it is not present
subprocess.run(["wget", "-q", "https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64", "-O", "cloudflared"])
subprocess.run(["chmod", "+x", "cloudflared"])
# Launch tunnel and print the output so you can find your public URL
print("Launching Cloudflare trycloudflare tunnel...")
process = subprocess.Popen(['./cloudflared', 'tunnel', '--url', 'http://127.0.0.1:11434'], stdout=subprocess.PIPE, stderr=subprocess.STDOUT, text=True)
for line in iter(process.stdout.readline, ''):
if "trycloudflare.com" in line:
print("\nYour Public Ollama API Endpoint is:")
print(line.strip())
print("\nUse this URL directly in SillyTavern or other API clients!\n")
threading.Thread(target=establish_cloudflare_tunnel, daemon=True).start()
If you seek a more stable, persistent connection that preserves the endpoint URL across notebook restarts, you can install InstaTunnel using the node environment in Colab:
# Install InstaTunnel CLI globally
!npm install -g instatunnel
# Run tunnel with a custom name and rate-limiting password protection
!it --name custom-uncensored-api --port 11434 --password your_api_password
This is built on the QUIC protocol (UDP multiplexing), entirely bypassing the TCP-over-TCP Head-of-Line (HOL) blocking latency tax that slows down standard tunneling scripts.
There is also a newer class of tunnel services promising persistence, custom subdomains, and better streaming behavior. Some of them are useful, but none of them change Colab's underlying truth: the runtime can still vanish. A stable domain on top of unstable compute is simply cosmetic coverage for volatility, and that is fine as long as you admit it.
The real bottleneck is not download speed
Rather than model download times, the real bottleneck is rehydration, because sessions die and local disk space vanishes. The primitive answer is mounting Google Drive, which remains the default because it is nearby rather than because it is good: huge model files on Drive frequently lead to I/O throttling, quota limitations, and slow startup paths.
If you actually plan to reuse the setup, external object storage is the saner pattern. A mounted file layer or direct object fetch from S3-compatible storage removes a lot of repeated pain. The point is not to pretend Colab is persistent; the point is to make runtime death less expensive—a distinction that saves hours of setup time.
What does performance feel like in practice?
A T4 is old enough that every benchmark table wants you to laugh at it. Ignore the theater: for chat workloads, it can still do useful work.
A good 8B or 9B quantized model will usually land in the range where interactive roleplay, summarization, and scripting feel alive instead of ceremonial. The realistic target is a single-user or low-concurrency pipe that can keep up with a human being, not a low-latency production endpoint for thousands of users. That is an achievable target.
Where the setup starts feeling bad is long context, aggressive parallelism, and the habitual mistake of treating a free notebook like a rented cluster. The free tier is forgiving right up to the moment it stops being forgiving at all.
The anti-abuse ceiling is the whole business model
This part matters more than any command snippet: Colab free tier exists because Google wants notebook-style experimentation, not free permanent inference hosting for the public internet. If your endpoint starts behaving like a real public service, you are colliding with the reason quotas exist.
Defeating Idle Disconnects
Google monitors interactive activity inside the browser window to prune inactive runtimes. If you walk away for more than 30 to 40 minutes, the notebook halts. To circumvent this, open your browser's Developer Tools Console (F12 or Cmd+Option+I -> Console tab) and run the following anti-disconnect heartbeat script:
function maintainColabHeartbeat() {
console.log("Simulating activity to prevent idle disconnect...");
// Target the connection button shadow root to simulate click events
const connectBtn = document.querySelector("colab-connect-button");
if (connectBtn && connectBtn.shadowRoot) {
const innerBtn = connectBtn.shadowRoot.querySelector("#connect");
if (innerBtn) innerBtn.click();
}
}
// Run the heartbeat trigger every 60 seconds
setInterval(maintainColabHeartbeat, 60000);
While this script successfully prevents idle state timeouts, it cannot bypass the absolute twelve-hour hard session ceiling. You must expect and plan for daily infrastructure resets.
So treat the system like a personal workstation in the cloud: keep traffic low, keep access private, avoid public sharing, and accept that sessions end. Anything else is wishful thinking dressed as architecture.
There are plenty of forum posts from people trying to outsmart idle policies, stretch runtimes, or keep a tab artificially alive forever. Even when those tricks appear to work, they never solve the hard limit. Colab is a preemptible machine. Build like a tenant, not like a squatter.
When Colab is smarter than local hardware
This answer irritates local-purist people, but the answer is: more often than they admit.
Colab is the better move when you are still exploring model families, testing frontends, benchmarking prompt formats, or figuring out whether a workload deserves its own GPU at all. Paying zero up front to answer those questions is rational.
Furthermore, it is useful when your main machine is weak, your travel setup is thin, or your actual goal is to control the model stack rather than to maximize sovereignty.
Privacy is the limit case. If the workload is truly sensitive, Colab loses immediately. Your prompts transit someone else's infrastructure. Your runtime exists on someone else's machine. That should end the argument.
But plenty of users are not choosing between perfect privacy and perfect convenience. They are choosing between a censored SaaS chat endpoint and a temporary open-model server they control well enough to route through their own tools. In that narrower contest, Colab makes sense.
When the free setup stops being clever
There is a point where free becomes expensive in a different currency.
If you need predictable uptime, fixed endpoints, longer context, heavier models, or sustained daily use, the improvisation tax begins to dominate the savings. That is the migration threshold. At that point you either pay for better hosted inference, pay for Colab Pro-class hardware, or buy local hardware and own the whole stack.
The correct signal is not frustration in the abstract. It is repeated operational friction.
If you keep rebuilding the same notebook, keep losing sessions mid-work, keep trimming context to fit the T4 envelope, and keep wishing the endpoint behaved like a machine you actually control, then you have already discovered the limit.
Colab did its job. It bought you time and clarity.
Free Colab LLM hosting is worth doing in 2026 for one reason: it is still the fastest way to get from zero hardware to a personally controlled open-model API. That does not make it durable, private, or business-grade, but it does make it useful—and that is enough.
If you keep the scope personal, choose a model that fits the T4 honestly, expose the endpoint through a sane tunnel, and treat persistence as a problem to reduce rather than solve, Colab remains one of the most effective cheap laboratories in the stack.
The mistake is expecting permanence from a system whose entire economic logic depends on impermanence.
Continue Reading
Related Guides
Best Local LLM for 8GB VRAM: Optimal Settings for AI Roleplay & ERP
A blunt 2026 guide to making 8GB cards work for local roleplay: what fits, what slows down, and which settings actually earn their place.
Run Local LLM on Mobile: Cloudflare Tunnel & Ngrok Setup Guide for AI Chat
A 2026 mobile access guide for local LLMs covering Cloudflare Tunnel, Ngrok, latency, security hardening, and the cleanest ways to reach a desktop model from a phone.
Local LLM on Mac: Setup Guide for Uncensored AI Roleplay (Apple Silicon M-Series)
A 2026 Mac guide for local roleplay stacks covering unified memory, model sizing, MLX versus llama.cpp, thermal limits, and clean Apple Silicon setup paths.
Ready for private AI?
Experience zero-log, client-side encrypted AI roleplay directly in your browser.
Launch App